






Apsara
编辑
阿里Apsara
1.apsara架构
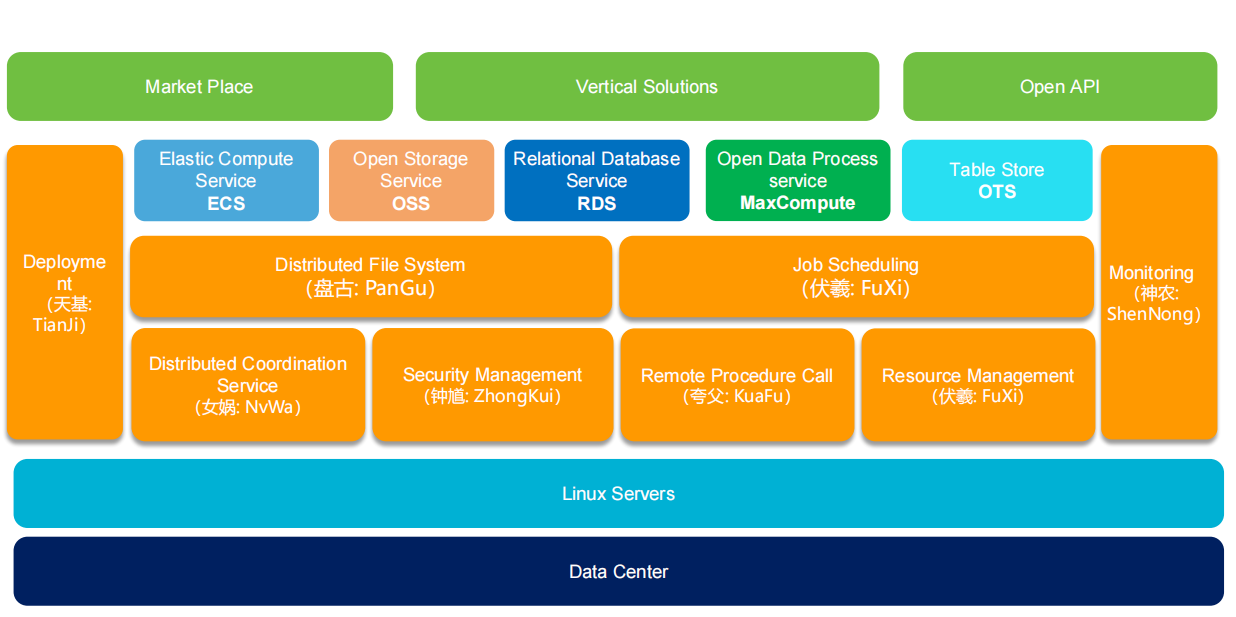
1.1. 底层 - 数据中心与服务器
Data Center:数据中心是阿里云的基础设施,提供物理硬件和网络环境支持,存储和运行所有的计算资源。
Linux Servers:数据中心中的物理服务器通常运行 Linux 操作系统,用于承载和运行所有上层的云计算和存储服务。这一层是 Apsara 系统的物理基础。
1.2. 基础设施层
Distributed File System(盘古,PanGu):盘古是阿里云的分布式文件系统,负责在阿里云大规模集群上管理存储资源。它通过多副本存储保证数据的可靠性和高可用性。
Job Scheduling(伏羲,FuXi):伏羲是阿里云的作业调度系统,负责在大规模分布式系统中调度任务和分配计算资源,以保证任务的高效执行。
Resource Management(伏羲,FuXi):伏羲同时也负责资源管理,动态分配计算资源,确保在高峰期也能弹性扩展,合理利用服务器资源。
Distributed Coordination Service(女娲,NvWa):女娲是阿里云的分布式协调服务,负责在集群中协调不同的任务、管理节点之间的通信和一致性。
Security Management(钟馗,ZhongKui):钟馗负责安全管理,确保云平台的安全性,包括身份认证、权限管理、数据加密等功能。
Remote Procedure Call(夸父,KuaFu):夸父是远程过程调用(RPC)框架,用于在分布式系统中实现高效的节点间通信。
Monitoring(神农,ShenNong):神农是阿里云的监控系统,负责实时监控平台的运行状态、健康状况,确保系统在出现故障时能够及时发现和处理。
Deployment(天基,TianJi):天基是阿里云的部署系统,支持自动化和批量化的应用部署,帮助用户快速上线和更新应用。
1.3. 服务层
Elastic Compute Service(ECS):ECS 是阿里云的弹性计算服务,提供可扩展的虚拟服务器(类似于 AWS 的 EC2),用户可以根据需要动态增加或减少计算资源。
Open Storage Service(OSS):OSS 是阿里云的对象存储服务,用户可以在 OSS 中存储和管理海量的非结构化数据,如图片、视频、备份等。
Relational Database Service(RDS):RDS 是阿里云的关系型数据库服务,支持 MySQL、SQL Server、PostgreSQL 等数据库类型,并提供自动备份、恢复、扩展等功能。
Open Data Process Service(MaxCompute):MaxCompute 是阿里云的大数据计算平台,支持大规模数据处理和分析,适用于批处理任务、数据仓库和大数据分析。
Table Store(OTS):OTS 是阿里云的表格存储服务,支持结构化数据存储,类似于分布式数据库,适合需要高吞吐和低延迟的场景。
1.4. 市场与解决方案层
Market Place:阿里云市场为用户提供各种第三方软件、服务和解决方案,用户可以在云市场中快速购买和部署应用。
Vertical Solutions:阿里云的垂直行业解决方案,针对特定行业如金融、电商、医疗等,提供定制化的云服务解决方案。
Open API:阿里云提供开放的 API,允许用户通过编程接口来管理和使用阿里云的各种服务。这一层的开放性使得开发者可以集成自己的应用程序到阿里云平台中。
2.Apsara ECS 底层
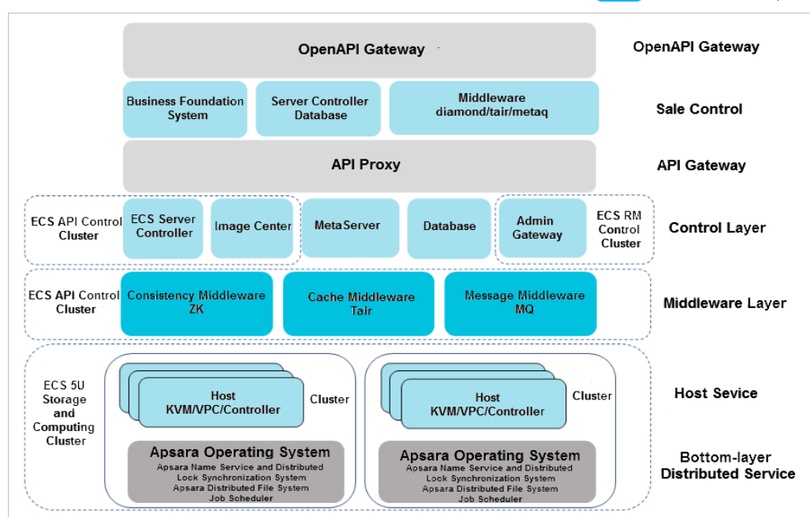
2.1. OpenAPI Gateway(开放 API 网关层)
Business Foundation System: 业务基础系统,处理阿里云的基础业务操作。
Server Controller Database: 服务器控制器数据库,用于存储和管理服务器的控制和配置信息。
Middleware: 包含中间件服务(如 diamond/tair/metaq),这些中间件用于处理消息传递、缓存等云计算服务的核心功能。
这一层是与用户直接交互的 API 层,通过开放的 API 网关,用户可以调用 ECS 等云服务。
2.2. Control Layer(控制层)
ECS API Control Cluster: 该集群负责 ECS 的 API 控制,用户的 API 请求会首先通过这个层来管理和处理。
ECS Server Controller: ECS 服务器控制器,负责管理虚拟机的生命周期,包括启动、停止、重启等操作。
Image Center: 镜像中心,存储和管理用户使用的系统镜像或应用镜像。
MetaServer: 元数据服务器,负责存储和管理虚拟机或计算节点的元数据信息。
Admin Gateway: 管理网关,提供管理员控制台的访问和管理功能。
Consistency Middleware ZK: 一致性中间件,类似于 Zookeeper,负责在分布式系统中保证节点状态一致。
Cache Middleware Tair: 缓存中间件 Tair,提供高效的缓存服务,支持分布式缓存存储。
Message Middleware MQ: 消息中间件(如消息队列 MQ),用于处理异步消息传递,确保任务高效调度和执行。
2.3. Middleware Layer(中间件层)
这一层由多个中间件模块组成,如一致性中间件、缓存中间件和消息中间件,用于协调和处理 ECS 和其他服务的通信和资源调度。
2.4. Host Service(主机服务层)
Host KVM/VPC/Controller: 主机层负责管理物理服务器的虚拟化和控制。这里的 KVM 表示虚拟机管理程序,VPC 表示虚拟专用网络,Controller 表示控制服务。
这个层次是直接负责运行虚拟机实例、网络实例以及控制服务的核心部分。
2.5. Bottom-layer Distributed Service(底层分布式服务层)
Apsara Operating System(飞天操作系统): 这是阿里云的分布式云操作系统。它负责管理底层的分布式存储、作业调度、锁同步等服务,确保资源的高效使用和分布式任务的可靠执行。
其中提到的核心组件包括:
Name Service: 名称服务,管理集群中的节点命名和识别。
Lock Synchronization System: 锁同步系统,确保分布式环境下多个节点的一致性。
Distributed File System: 分布式文件系统(如盘古),负责提供可靠的分布式数据存储服务。
Job Scheduler: 作业调度器,负责调度大规模分布式计算任务。
3. Pangu盘古分布式文件系统

Pangu 是一种分布式文件系统,旨在整合大量通用计算资源来为用户提供大规模、高可靠性、高可用性、高吞吐量和可扩展的存储服务。它是 Feitian 内核 的重要组成部分。
3.1 系统特性:
大规模(Massive):
支持的存储规模:Pangu 文件系统支持规模达 数十 PB(1 PB = 1000 TB)的存储。
文件数量:支持文件数量达到 数亿 级别。
高可靠性(High Reliability):
多节点存储:所有数据存储在多个节点的不同机架上(通常设置为 3 个)。即使集群中的某些节点发生硬件或软件故障,系统也能够检测到故障并自动进行数据备份和迁移。
元数据可靠性:数据和元数据是持久化的,保证数据可以正确访问。
高可用性(High Availability):
无中断访问:即使在硬件或软件故障、异常、系统升级的情况下,Pangu 系统仍能无中断访问数据,并最大限度地减少不可服务时间。
高扩展性(High Scalability):
自动扩展容量:系统的容量可以通过自动增加机器进行扩展,存储在离线机器上的数据会自动迁移到新添加的节点。
4.apsara弹性伸缩
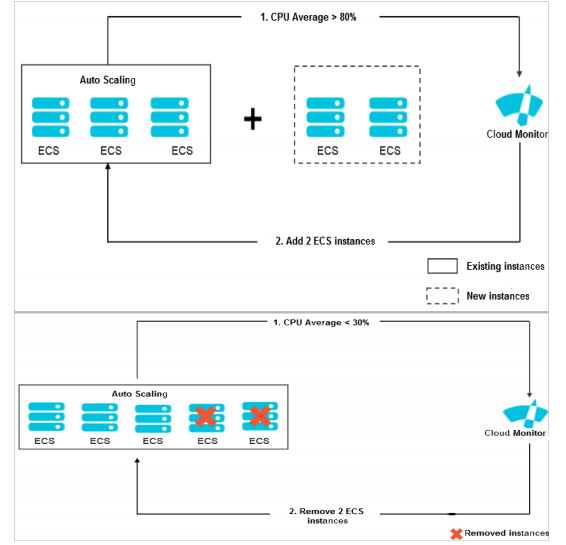
4.1 架构
自动伸缩(Auto Scaling) 是一种根据系统负载动态调整 弹性计算服务(ECS) 实例数量的机制。
当 CPU 平均使用率超过 80% 时,系统会自动添加两个 ECS 实例以应对增加的需求,图片中显示了现有实例旁边新增的两个实例。
相反,当 CPU 平均使用率低于 30% 时,为了优化资源使用并降低成本,系统会移除两个 ECS 实例,图片中标有 "X" 的实例即表示被移除的实例。
4.2 概述
自动伸缩 是一种管理服务,根据业务需求自动调整 ECS 实例的数量。
它基于预定义的规则,确保在业务负载增加时,系统具备足够的计算资源。当业务负载减少时,自动伸缩功能会移除多余的 ECS 实例以节省运行成本。
4.3 优势
实例自动伸缩:根据实际使用情况动态调整 ECS 实例的数量。
实时监控实例:自动替换不健康的实例,确保系统正常运行。
智能白名单管理:无需用户干预,自动控制 ECS 实例的伸缩。
多种可自定义的伸缩模式:根据具体业务需求定制不同的伸缩模式。
4.4 适用场景
自动伸缩特别适用于以下高负载场景:
视频流媒体、直播和广播。
游戏。
促销活动,如当用户流量激增时,系统需要额外的计算资源来支持。
5.CDN内容分发网络

5.1 CDN 概述
内容分发网络 (CDN) 是一种网络服务,可以将网站内容快速地传输到全球各地的终端用户。通过使用阿里云 CDN,可以有效地缩短网站响应时间至毫秒级,确保视频流媒体的流畅播放,并且能够处理大流量的访问。
5.2 性能 (Performance)
高速加速:适用于点播和直播媒体内容的高速加速。
页面优化和智能压缩技术:利用这些技术加速内容的分发。
减少响应时间:通过将多个 JavaScript/CSS 文件合并为一个请求,减少加载时间。
5.3 服务集成 (Service Integration)
OSS (对象存储服务):加速内容传输速度并降低分发成本。
ECS (弹性计算服务):提高内容可用性,保护原始内容,并减少带宽消耗。
SLB (负载均衡服务):当源站地址需要访问数据时,分发负载以减少服务器压力。
6. ELastic Architecture
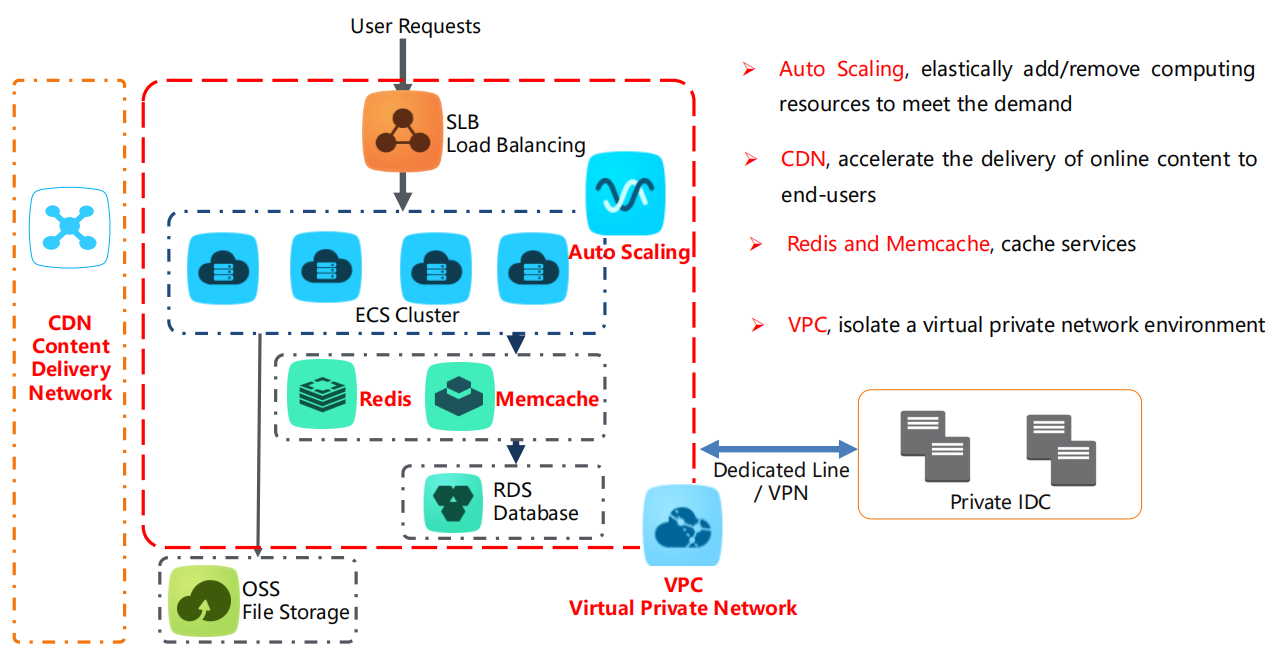
弹性架构
6.1. 用户请求和负载均衡(SLB Load Balancing)
用户请求首先进入 SLB 负载均衡,用于将流量分发到多个后端的 ECS 集群 上,以确保系统稳定性和高可用性。
6.2. 自动伸缩(Auto Scaling)
自动伸缩 功能可以根据实际需求,弹性地增加或减少 ECS 实例的数量,从而在用户请求量增加时添加计算资源,或者在需求降低时移除不必要的资源,确保资源使用的最优化。
6.3. CDN(内容分发网络)
CDN 负责加速在线内容的交付,将内容快速传输到全球用户,减少延迟并提升用户体验,尤其适用于需要处理大量流量的网站。
6.4. 缓存服务(Redis 和 Memcache)
Redis 和 Memcache 提供缓存服务,加快数据访问速度,减少数据库压力。通过将常用的数据存储在缓存中,可以显著提高系统性能。
6.5. OSS 文件存储
OSS(对象存储服务) 用于存储大文件、静态资源等。这类存储可以确保数据持久化,适用于文件的长期保存和高效访问。
6.6. 数据库(RDS)
RDS(关系型数据库服务) 提供高性能、稳定的数据库系统,负责处理用户请求所需的动态数据管理。
6.7. VPC(虚拟私有云网络)
VPC 允许用户在隔离的虚拟私有环境中管理云资源,确保网络的安全性和独立性。通过 专线或 VPN,VPC 可以与用户的 私有数据中心(Private IDC) 连接,构建混合云架构,实现私有资源和云端资源的互通。
7. VPC Virtual Private Cloud
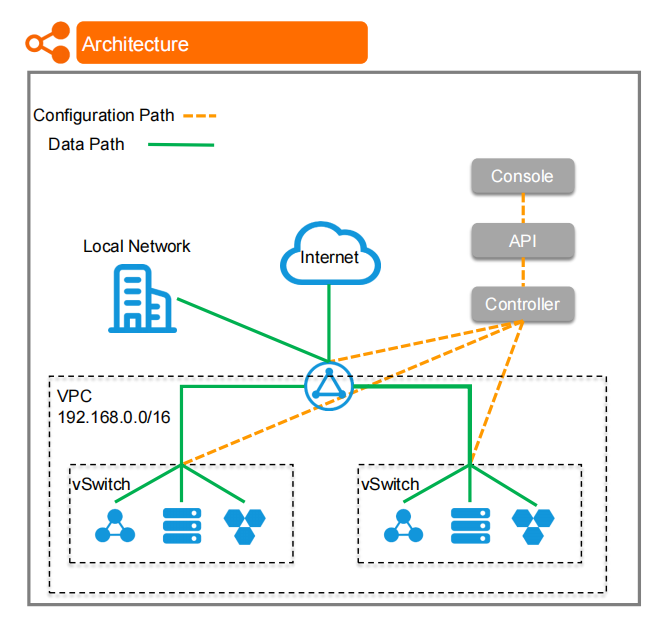
7.1. VPC(Virtual Private Cloud)
VPC 是一个虚拟的网络环境,IP 地址范围为 192.168.0.0/16,用于隔离和管理网络资源。VPC 内部可以包含多个 虚拟交换机(vSwitch),用于连接不同的计算资源和服务。
7.2. 虚拟交换机(vSwitch)
VPC 内部划分为多个子网,每个子网通过 vSwitch 进行网络连接。不同的资源如数据库、应用服务器等,都可以通过 vSwitch 连接和通信。
7.3. 控制路径(Configuration Path) 和 数据路径(Data Path)
控制路径(虚线橙色箭头):通过 Controller(控制器) 来管理和配置网络、资源和服务,使用 API 和 Console 进行交互。控制器负责配置网络路径、控制数据流量和管理资源。
数据路径(实线绿色箭头):表示实际的数据传输路径。数据可以从本地网络或互联网传输到 VPC 内的资源,或者在 VPC 内的不同资源间进行传输。
7.4. 本地网络(Local Network) 和 互联网(Internet)
本地网络通过 绿色箭头 与 VPC 进行通信,允许企业内部网络与云资源进行互联。
互联网同样通过 绿色箭头 与 VPC 内的资源通信,用户请求可以通过互联网进入 VPC 内的服务。
7.5. 控制台(Console)、API 和控制器(Controller)
这些组件负责管理和监控整个网络架构。用户可以通过 控制台(Console) 或 API 访问控制器,以配置和管理 VPC 内的网络资源、权限、负载均衡等。
8. ApsaraDB For Redis

ApsaraDB for Redis
ApsaraDB for Redis 是一种基于开源 Redis 的全托管数据库服务,专为高性能、高吞吐量的缓存和数据库应用设计。它支持多种 Redis 部署模式,具有高可用性和自动备份功能。
核心功能:
高性能缓存:适合需要快速响应和大数据量操作的应用,如会话管理、排行榜、消息队列等。
持久化存储:支持数据持久化功能,可以将数据定期保存到磁盘,以防止数据丢失。
高可用性:通过多节点部署和主从复制,确保数据的高可用性,系统可以在故障时快速恢复。
自动扩展:支持自动扩展,用户可以根据业务需求灵活调整实例的大小和性能。
适用场景:
实时分析:对于需要实时处理大量数据的场景,Redis 提供了高吞吐量和低延迟的数据访问。
缓存和数据库:Redis 可以用作内存数据库或缓存层,显著加快应用程序的数据处理速度。
消息队列:Redis 支持发布/订阅功能,适合构建消息队列系统。
9. CDN+Redis 使用案例
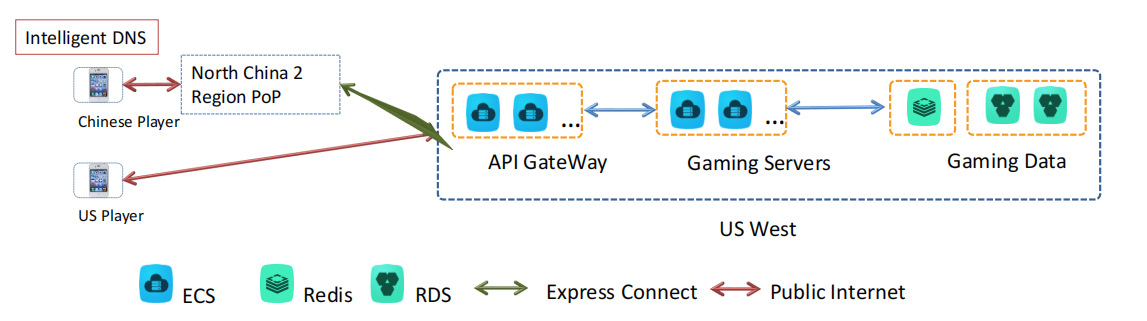
9.1 Intelligent DNS(智能 DNS)
智能 DNS 负责根据玩家的地理位置,将用户请求引导至最优的服务器。图中展示了中国和美国玩家通过 DNS 被路由到不同的区域。
9.2. 玩家访问路径
Chinese Player(中国玩家):通过公共互联网访问位于 华北 2 区域(North China 2 Region PoP) 的接入点(PoP),然后通过 Express Connect 连接至美国西部的 API 网关和游戏服务器。
US Player(美国玩家):通过公共互联网直接访问位于 美国西部(US West) 的游戏服务器。
9.3. API Gateway
API 网关:API 网关位于美国西部,用于管理所有来自玩家的请求,将请求分发到后端的游戏服务器。
9.4. Gaming Servers(游戏服务器)
游戏服务器:位于美国西部,处理游戏逻辑和实时交互。它与数据库和缓存服务紧密连接,以确保游戏数据的快速处理和存取。
9.5. Gaming Data(游戏数据)
Redis:提供缓存服务,加速游戏数据的读取与写入,适合高频访问的数据。
RDS:关系型数据库服务,用于存储结构化的游戏数据。
9.6. 网络连接
Express Connect:绿色箭头代表 Express Connect,这是一个专线连接,用于中国区域的玩家连接到美国的游戏服务器,确保数据传输的高速度和低延迟。
Public Internet(公共互联网):红色箭头表示通过公共互联网访问的路径,美国玩家通过互联网直接访问位于美国西部的游戏服务器。
10.阿里云原生服务概论
10.1 E-MapReduce:

作用:基于开源的 Apache Hadoop 和 Apache Spark,提供一站式大数据分析解决方案,主要用于大规模数据处理和分析。
AWS 对应服务:Amazon EMR (Elastic MapReduce),也是基于 Hadoop 和 Spark 的托管服务,用于处理大数据工作负载。
大规模数据处理:
基于 Hadoop 和 Spark 等分布式计算框架,支持处理TB到PB级别的海量数据。
多样的开源框架支持:
除了 Hadoop 和 Spark,E-MapReduce 还支持 Kafka 和 Storm 等流行的大数据工具,适合实时流处理和日志分析等场景。
集群管理:
提供自动化的集群管理功能,用户可以轻松启动、停止和扩展计算集群,按需使用资源。
与阿里云生态集成:
E-MapReduce 可以与阿里云的其他服务(如 OSS(对象存储服务)、RDS(关系型数据库服务) 和 DataWorks)无缝集成,形成完整的大数据处理方案。
多种计算模式:
支持批处理、流处理、图计算、机器学习等多种计算模式,满足不同的业务需求。
适用场景:
海量日志分析:快速处理和分析大规模日志数据,用于实时监控和决策支持。
数据仓库:支持企业级数据仓库建设,帮助组织实现高效的数据存储和分析。
机器学习:可以利用 Spark MLlib 等工具在分布式环境中进行机器学习任务。
流式处理:通过 Kafka 和 Storm,处理实时数据流,适合用于物联网、实时分析等场景。
10.2 Table Store:

作用:提供可扩展的、完全托管的 NoSQL 数据库服务,适合存储非结构化数据。
AWS 对应服务:Amazon DynamoDB,是 AWS 的 NoSQL 数据库服务,支持键值存储和文档数据库。
核心功能:
分布式架构:
Table Store 采用分布式架构,支持海量数据的存储和快速查询,能够自动扩展以应对不断增长的数据规模。
NoSQL 数据库:
提供灵活的数据模型,允许存储结构化、半结构化和非结构化数据。
适合不需要固定模式的应用场景,具有高吞吐量和低延迟的访问能力。
多种数据模型:
支持多种数据模型,包括宽表模型、时间序列数据模型等,可以根据具体应用场景选择合适的数据模型来优化存储和访问效率。
强一致性与高可用性:
Table Store 通过多副本机制保障数据的强一致性和高可用性,确保用户的数据不会因为节点故障而丢失。
秒级查询:
无论数据量有多大,Table Store 都能实现秒级的查询响应,适合需要实时数据访问的应用场景。
全托管服务:
用户无需管理底层的硬件和基础设施,Table Store 提供了全托管的数据库服务,自动完成扩展、备份、恢复等操作。
适用场景:
物联网(IoT)数据管理:
Table Store 支持存储和查询大量的物联网传感器数据,并能够实时处理这些数据,为设备监控和分析提供支持。
日志存储与分析:
非结构化的日志数据可以方便地存储在 Table Store 中,帮助企业进行日志分析和安全监控。
社交媒体与内容管理:
适合社交媒体、评论系统等需要处理大量用户生成内容的场景,能够存储和快速检索这些内容。
时间序列数据存储:
Table Store 能够有效存储时间序列数据,如股票行情、设备监控数据等,提供高效的查询和分析能力。
10.3 Quick BI:

作用:帮助用户进行数据分析、探索和报告,帮助企业用户做出数据驱动的决策。
AWS 对应服务:Amazon QuickSight,一个快速、易于使用的商业智能服务,支持数据可视化和报告生成。
核心功能:
数据分析与可视化:
Quick BI 支持对企业内外部数据进行快速分析,帮助用户创建直观的数据可视化图表和仪表盘,如柱状图、折线图、饼图等多种图表类型。
自助式报表生成:
用户可以根据业务需求,灵活地设计并生成报表,无需依赖复杂的代码或专业技术人员。报表可以进行定制并定期自动生成。
多数据源支持:
Quick BI 能够连接多种数据源,如云数据库、关系型数据库(RDS)、NoSQL 数据库、Excel 表格等,实现多源数据整合和统一分析。
拖拽式操作:
提供拖拽式界面,用户无需编写复杂的 SQL 查询语句,只需通过简单的拖拽操作就可以进行数据探索、分析和报表设计,非常适合非技术用户。
实时数据分析:
支持实时数据分析,能够连接实时数据源,帮助用户动态监控业务变化并快速做出反应。
数据安全与权限管理:
提供完善的数据权限管理功能,确保不同层级的用户能够访问相应的数据,保障企业数据的安全性和合规性。
移动端支持:
Quick BI 还支持移动端,用户可以随时随地在手机或平板上查看数据报表和仪表盘。
适用场景:
企业业务决策:
通过分析财务数据、销售数据、用户行为等,帮助企业领导层做出基于数据的决策,提高业务效益。
运营监控:
实时监控企业的运营数据,通过可视化图表快速了解企业各部门的关键业务指标(KPI),及时发现问题并作出调整。
市场分析:
快速处理和分析市场数据、用户行为数据等,帮助企业进行市场洞察、客户细分和产品优化。
报表自动化:
企业可以使用 Quick BI 创建自动生成的定期报表,减少手工报表的工作量,并确保数据更新的及时性和准确性。
10.4 MaxCompute:

作用:提供全托管的、多租户数据处理平台,适用于大规模数据仓储。
AWS 对应服务:Amazon Redshift,是 AWS 提供的完全托管的云数据仓库服务,用于大规模数据分析。
核心功能:
大规模数据处理:
MaxCompute 能够处理 PB 级别的数据量,适用于海量数据的存储和分析,尤其适合企业级的数据仓库场景。
多租户架构:
提供多租户架构,支持多个用户同时访问并使用数据资源,同时确保数据的隔离和安全性。
分布式计算:
MaxCompute 使用分布式计算框架,能够快速处理大规模的数据计算任务,支持批量数据处理、复杂查询和统计分析。
多语言支持:
支持 SQL 语言、UDF(用户定义函数)、MapReduce、Python 等多种编程语言和框架,方便用户根据具体需求进行开发和操作。
高安全性:
MaxCompute 提供完善的数据安全保障,包括数据加密、访问控制、日志审计等功能,确保数据在存储和传输过程中的安全性。
自动扩展和维护:
平台提供自动化的集群管理功能,无需用户手动进行扩展或维护,降低运维成本。
与阿里云生态集成:
MaxCompute 能与阿里云的其他服务无缝集成,如 DataWorks(大数据开发与治理平台)、E-MapReduce(分布式大数据处理)等,形成完整的大数据处理链路。
适用场景:
企业级数据仓库:
MaxCompute 能够存储和处理企业的海量结构化和非结构化数据,提供高效的数据仓储解决方案,帮助企业进行全局的数据分析和决策支持。
大数据分析:
适合大规模的数据分析、商业智能(BI)、实时数据处理等,帮助企业发掘数据的潜在价值。
机器学习:
MaxCompute 支持分布式的机器学习算法,能够处理大规模的训练数据集,适用于推荐系统、数据挖掘、预测分析等场景。
日志分析与监控:
可以用于大规模日志的存储与分析,帮助企业实时监控系统状态、用户行为分析以及安全审计等。
10.5 DataWorks:

作用:一个提供大数据开发和治理的集成平台,支持 MaxCompute 和 E-MapReduce 等大数据计算引擎。
AWS 对应服务:AWS Glue,是 AWS 提供的托管 ETL(提取、转换、加载)服务,用于数据集成和数据治理任务。
核心功能:
数据开发:
DataWorks 提供了可视化的开发环境,用户可以使用 SQL、Python 等多种语言编写数据处理任务,支持任务的调度和运行管理。
支持多种大数据计算引擎,如 MaxCompute、E-MapReduce、Hologres,方便用户开发各种类型的批处理和实时处理任务。
数据集成:
提供强大的数据集成功能,可以将来自多个数据源的数据,如 关系型数据库、NoSQL 数据库、API、文件存储等,进行整合,并在不同数据源之间实现数据同步。
任务调度与自动化:
支持复杂的数据任务调度,包括定时任务、依赖任务和分层任务调度。可以通过简单的配置,实现数据处理流程的全自动化,确保数据定期更新与处理。
数据质量与治理:
DataWorks 提供数据质量监控工具,帮助企业在数据处理的每个阶段进行数据校验、检测和质量控制,保证数据的准确性、一致性和完整性。
支持数据的权限管理和合规性控制,确保数据在整个生命周期中符合企业的安全和隐私要求。
数据可视化与报表:
通过与 Quick BI 等工具集成,用户可以轻松创建数据可视化报表和仪表盘,进行数据的可视化展示和分析,帮助企业快速获取数据洞察。
数据运维:
DataWorks 提供完善的运维工具,包括作业监控、日志跟踪、告警机制等,帮助开发者及时发现和解决数据任务执行中的问题。
灵活扩展:
DataWorks 可以无缝集成阿里云的其他大数据服务(如 MaxCompute、OSS、RDS 等),用户可以根据业务需求灵活扩展数据处理能力。
适用场景:
数据工程与ETL流程:
帮助企业设计和自动化数据抽取、转换、加载(ETL)流程,适合大规模的数据集成与数据清洗场景。
数据仓库构建:
DataWorks 支持数据仓库的全流程开发,适用于构建企业级数据仓库,能够管理不同数据源并统一进行处理和分析。
大数据治理:
通过数据质量管理和权限控制,DataWorks 可以帮助企业进行数据治理,确保数据在整个生命周期中的合规性和安全性。
数据开发与运维:
企业可以通过 DataWorks 进行数据任务的开发与运维,利用其强大的调度和监控功能,确保数据处理任务按计划顺利执行。
11.Big Data Product - MaxCompute 结构
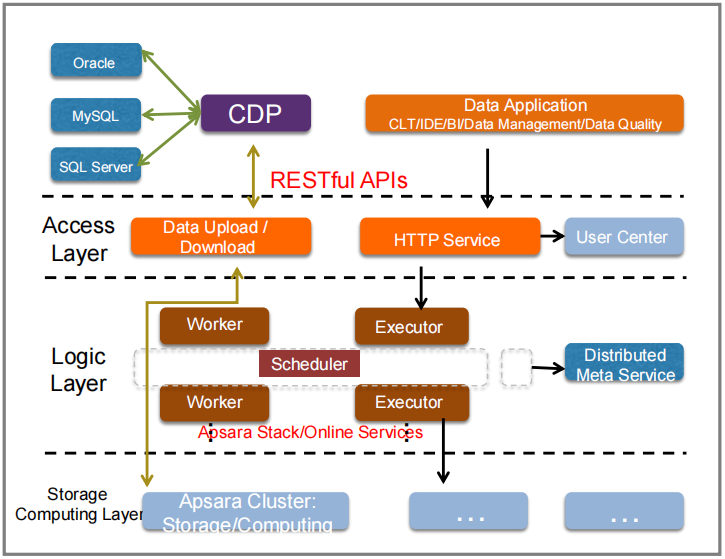
11.1. 数据来源(Data Sources)
数据可以来自多个不同的数据库系统,如 Oracle、MySQL 和 SQL Server,这些数据通过系统的中央数据平台(CDP)被接收并处理。
11.2. 访问层(Access Layer)
CDP(中央数据平台):负责从不同的数据源收集数据,并通过 RESTful APIs 提供给后续的服务。
数据上传/下载(Data Upload / Download):用于将数据从存储层上传或下载至逻辑层进行处理。
HTTP 服务(HTTP Service):为用户中心提供服务,处理用户的请求并与逻辑层交互。
数据应用(Data Application):包括多种数据管理和分析工具,如 CLT(命令行工具)、IDE、BI(商业智能)、数据管理 和 数据质量,这些应用可以直接访问数据并进行操作。
11.3. 逻辑层(Logic Layer)
Scheduler(调度器):调度整个系统的工作流程,确保不同任务的有序执行。
Worker 和 Executor:分别处理具体的任务和执行逻辑运算。Worker 负责与存储层进行交互,将数据拉取上来后交给 Executor 进行处理。两者之间有多个实例并行工作,保证了任务的高效处理。
分布式元数据服务(Distributed Meta Service):管理系统中的元数据(即描述数据的数据),确保数据的一致性和可追踪性。
11.4. 存储计算层(Storage Computing Layer)
Apsara Cluster:这是阿里云的基础设施,负责数据的存储和计算。所有的数据和计算任务最终都在这个集群中执行和完成。它为上层的 Worker 和 Executor 提供了计算和存储资源支持。
11.5 处理流程:
数据从不同的数据源(Oracle、MySQL、SQL Server)通过 CDP 进入系统。
数据可以通过 数据上传/下载 模块传输到 逻辑层,并经过 Worker 和 Executor 的处理。
Scheduler(调度器) 控制任务的执行流程,确保任务有序并行进行。
处理完的数据最终被存储在 Apsara Cluster 中。
分布式元数据服务 管理并跟踪系统中所有数据的元信息,确保数据在不同模块之间的一致性。
用户可以通过 HTTP 服务 或 数据应用 层使用工具(如 BI 或 IDE)访问处理后的数据。
12.Enterprise Architecture
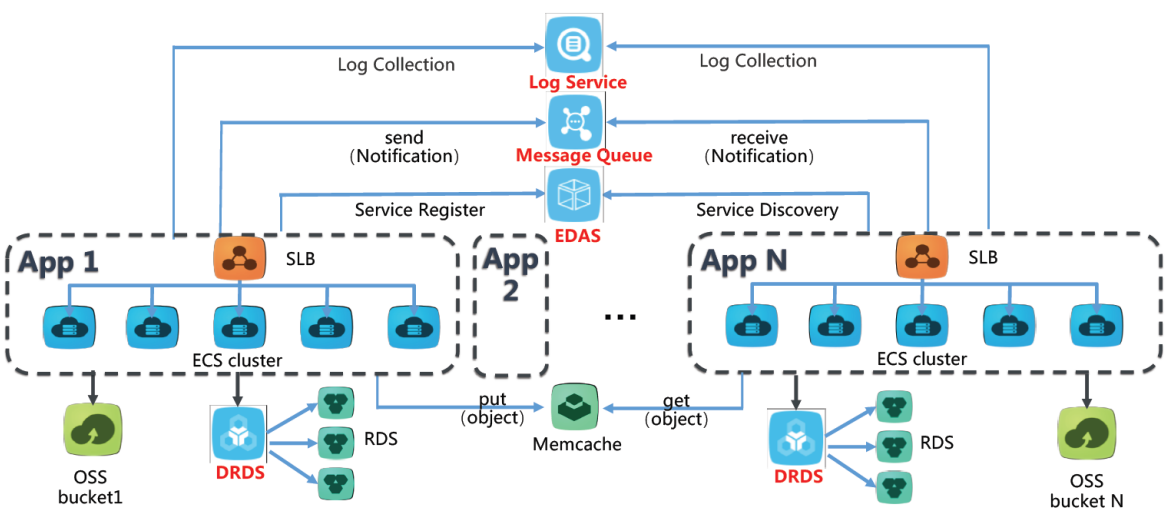
12.1. 应用层(App Layer)
每个应用(App 1 到 App N)都是部署在一个 ECS 集群 上,通过负载均衡器(SLB)来分配流量到集群中的各个实例。
每个应用与 RDS(关系型数据库服务) 和 DRDS(分布式关系型数据库服务) 进行连接,用于处理数据库相关的操作。
对象存储服务 OSS 用于存储大文件或静态资源,应用可以通过 PUT 和 GET 操作与 OSS 交互。
Memcache 提供缓存服务,用于快速存储和读取经常使用的数据,减少数据库的压力。
12.2. 中间件和消息处理
EDAS(企业级分布式应用服务):负责应用的服务注册和服务发现,帮助多个应用进行通信和管理。
Message Queue(消息队列):用于发送和接收通知,确保各个应用之间的消息传递和异步处理。通过消息队列,可以实现解耦、负载均衡和任务调度。
12.3. 日志服务
Log Service:负责日志的收集和管理。每个应用的日志都会被收集到日志服务中,便于后续的分析和监控。
12.4. 负载均衡(SLB)
每个应用都有一个独立的 SLB(Server Load Balancer),用于将来自外部的流量分配给 ECS 集群中的多个服务器,确保流量均衡和高可用性。
12.5. 数据存储和缓存
RDS 和 DRDS:RDS 是关系型数据库,适用于处理结构化数据;DRDS 是分布式关系数据库,适合大规模的数据存储和查询。
OSS:对象存储用于存储文件和其他对象,具有高扩展性和低成本的优势。
Memcache:提供了高性能的缓存服务,减少了直接访问数据库的负担,加快了数据的读取速度。
13.消息队列
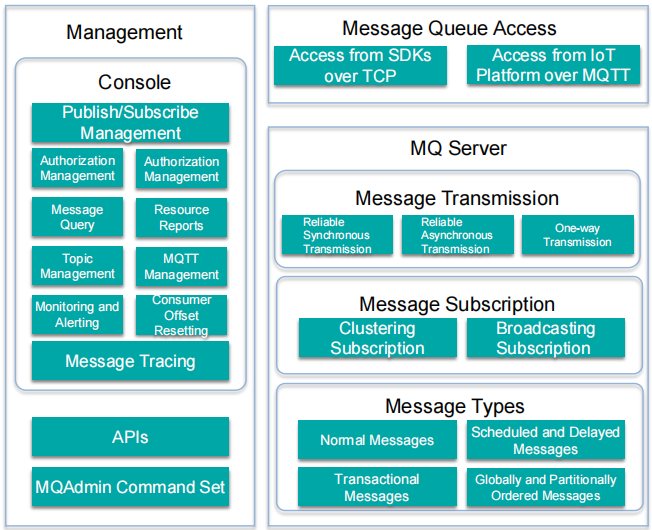
13.1. 管理(Management)
用于控制和监控消息队列系统的工具和接口:
控制台(Console): 用户可以在此管理发布/订阅配置。
授权管理(Authorization Management): 负责系统中不同组件的访问权限管理。
消息查询(Message Query): 允许用户查询系统中的消息。
资源报告(Resource Reports): 提供资源的跟踪和管理报告功能。
主题管理(Topic Management): 管理消息传递中的不同主题。
MQTT 管理(MQTT Management): 专门管理基于 MQTT 协议的消息。
监控与告警(Monitoring and Alerting): 用于跟踪系统健康状况,并设置告警以预防问题。
消费者偏移重置(Consumer Offset Resetting): 管理消费者的消息偏移重置。
消息追踪(Message Tracing): 提供对消息在系统中流转的详细跟踪。
API 和 MQAdmin 命令集: 提供通过编程接口(API)和命令行工具来配置和管理系统的方式。
13.2. 消息队列访问(Message Queue Access)
如何访问或与消息进行交互:
通过 SDK 通过 TCP 访问(Access from SDKs over TCP): 允许使用软件开发工具包(SDK)通过 TCP 连接进行集成。
通过 MQTT 从 IoT 平台访问(Access from IoT Platform over MQTT): 支持物联网设备通过 MQTT 协议访问消息队列,MQTT 是一个轻量级的消息传递协议,非常适合物联网应用。
13.3. 消息队列服务器(MQ Server)
核心的消息处理和管理功能:
消息传输(Message Transmission): 不同的消息传递方式:
可靠的同步传输(Reliable Synchronous Transmission): 保证消息实时传递并收到确认。
可靠的异步传输(Reliable Asynchronous Transmission): 确保消息发送和接收,但无需等待确认即可发送下一个消息。
单向传输(One-way Transmission): 简单的消息传输,不需要响应。
消息订阅(Message Subscription): 消费者如何订阅消息:
集群订阅(Clustering Subscription): 多个消费者组成一个组,消息只发送给组中的一个成员。
广播订阅(Broadcasting Subscription): 组中的所有消费者都能接收到消息。
13.4. 消息类型(Message Types)
系统支持的消息类型:
普通消息(Normal Messages): 没有特殊属性的标准消息。
事务消息(Transactional Messages): 确保系统之间一致性的事务消息。
定时和延时消息(Scheduled and Delayed Messages): 经过预定延迟后发送的消息。
全局和分区有序消息(Globally and Partitionally Ordered Messages): 确保消息按全局或分区的顺序进行传递。
14. EDAS Distributed Middleware (Microservices)
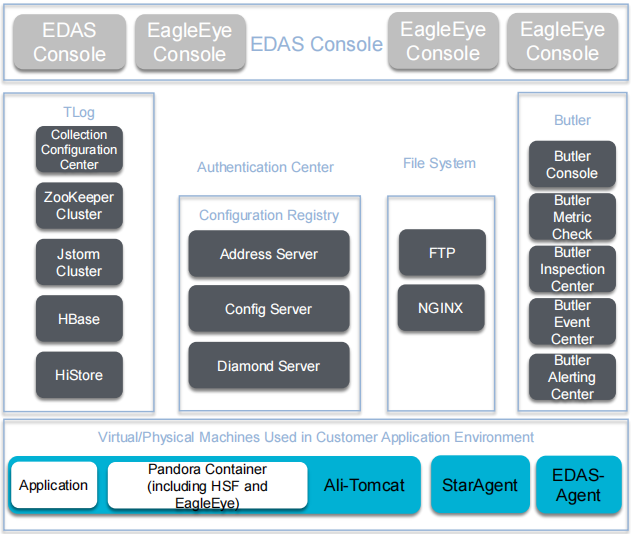
14.1. EDAS Console 和 EagleEye Console
EDAS Console: 提供用户界面,允许开发者和运维人员对分布式应用进行管理和监控。
EagleEye Console: 专门用于分布式系统的日志收集、链路追踪以及监控服务。EagleEye 提供了全面的监控解决方案,帮助排查系统问题。
14.2. TLog(日志管理部分)
负责收集和管理系统中的日志信息,提供故障排查和性能分析的基础。
包含多个组件:
Collection Configuration Center: 配置和管理日志收集规则。
ZooKeeper Cluster: 分布式协调服务,用于服务注册、发现和配置管理。
Jstorm Cluster: 实时流处理平台,用于处理和分析日志数据。
HBase: 分布式数据库,通常用于存储日志和追踪数据。
HiStore: 一种分布式存储系统,用于存储大量的日志数据。
14.3. 认证中心(Authentication Center)
提供身份认证和权限管理服务,确保不同用户和应用在访问系统时的安全性。
14.4. 配置注册中心(Configuration Registry)
这一部分包含多个服务器,主要用于管理分布式系统中的配置和服务注册:
Address Server: 用于管理应用的地址信息。
Config Server: 管理应用的配置数据。
Diamond Server: 一个配置中心,用于统一管理和分发分布式应用的配置。
14.5. 文件系统(File System)
管理分布式系统中的文件存储和传输:
FTP: 用于文件传输协议的实现。
NGINX: 高性能的反向代理服务器和静态资源服务器,处理静态文件的分发和管理。
14.6. Butler(运维管理部分)
Butler 模块主要负责系统的运行监控和告警管理:
Butler Console: 提供运维人员对系统的整体视图和管理操作。
Butler Metric Check: 负责检查和监控系统的运行指标。
Butler Inspection Center: 进行系统健康状况的检查和分析。
Butler Event Center: 事件管理中心,用于处理和记录系统中发生的事件。
Butler Alerting Center: 告警中心,提供异常情况的通知和处理。
14.7. 虚拟/物理机器环境(Virtual/Physical Machines Environment)
该部分展示了分布式应用部署在实际环境中的组件:
Application: 运行在容器中的实际应用程序。
Pandora Container(包含 HSF 和 EagleEye): 阿里巴巴的分布式服务框架 HSF,以及 EagleEye 链路追踪工具被打包在 Pandora 容器中,提供微服务的管理与追踪。
Ali-Tomcat: 阿里巴巴定制的 Tomcat 服务器,用于运行 Java 应用程序。
StarAgent: 一个代理工具,用于收集系统性能和运行状态信息。
EDAS-Agent: 负责应用的管理、监控和自动化运维。
15.stateless 和 stateful
15.1. 无状态(Stateless)
无状态系统或服务在处理每个请求时,不会保留任何与先前请求相关的上下文或状态。每个请求都是独立的,服务器不会记住客户端之前的交互历史。
特点:
请求独立性:每个请求都是独立的,服务器在处理请求时不依赖于之前的请求。换句话说,服务器不需要知道之前发生了什么。
简化设计:由于不需要保存状态,服务的实现相对简单,特别适合扩展。
更容易扩展:因为每个请求都是独立的,所以可以轻松地将服务部署在多个服务器上,实现负载均衡。
无状态协议示例:HTTP 协议就是一个典型的无状态协议。每个 HTTP 请求都是独立的,服务器不会自动保存上一次请求的任何信息。
优点:
扩展性强:多个请求可以分布到不同的服务器处理,不依赖于任何特定服务器。
容错性高:如果某个服务器崩溃或失效,由于不保存状态,可以很容易地将请求重定向到其他服务器。
简化维护:不需要维护客户端状态,因此系统复杂度降低。
缺点:
无上下文:由于每个请求没有上下文信息,客户端可能需要在每次请求中包含更多的参数或数据,这增加了带宽和计算开销。
状态管理依赖外部机制:如果需要维持会话(如用户登录状态),通常需要使用外部机制(如 cookies、token 或数据库)来管理。
无状态系统的应用场景:
RESTful API:REST 通常是无状态的,每个 API 请求都包含了所有需要的上下文信息。
静态文件请求:例如在网站中,每次请求静态资源(图片、CSS、JavaScript)时,服务器不需要记住用户之前请求了哪些内容。
15.2. 有状态(Stateful)
有状态系统或服务在处理请求时会保留与客户端的交互历史或状态信息。每个请求的处理可能会依赖之前请求的上下文。
特点:
请求之间有关联:每个请求都与之前的请求相关,服务器会保存一些上下文信息,例如用户会话、购物车内容等。
复杂性增加:由于需要保存状态,系统需要维护更多的数据,并且可能需要额外的资源来存储这些状态。
状态恢复:如果服务器崩溃或重新启动,必须有机制恢复之前的状态,否则会丢失上下文信息。
优点:
连续性:由于服务器保存了状态信息,客户端不需要在每次请求中重复提供所有信息。可以实现复杂的交互,例如会话管理、游戏状态管理等。
用户体验更好:有状态系统可以在多个请求之间维护用户状态,提供更一致和连续的用户体验。
缺点:
扩展性较差:由于请求之间是有依赖的,将其分布到多个服务器上处理会比较困难。服务器必须共享或同步状态信息,复杂度增加。
容错性较差:如果一个有状态的服务器失效,客户端可能会丢失状态或需要重新建立连接。
管理成本较高:服务器需要额外的机制来处理状态的持久化、恢复和同步。
有状态系统的应用场景:
在线购物系统:在电子商务网站中,购物车通常是有状态的。用户添加商品到购物车后,服务器会记住这些信息,直到用户完成购买或清空购物车。
即时通信应用:在聊天应用中,服务器需要保存用户的会话状态,记录消息的发送和接收情况。
数据库连接:有状态的数据库连接需要在多个事务之间保持用户的身份和会话信息。
总结对比:
16.Typical Solution Practice经典解决方案架构
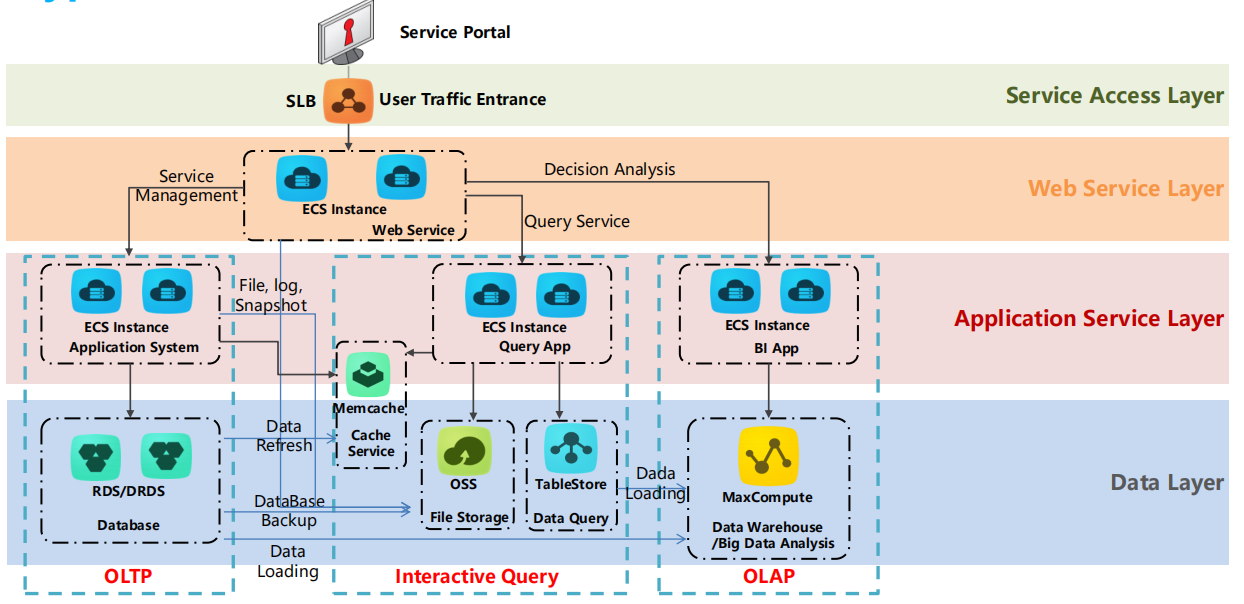
16.1. Service Access Layer(服务访问层)
Service Portal(服务门户):用户通过门户访问系统,发起请求。
SLB(Server Load Balancer,服务器负载均衡):将用户的流量均衡地分配到后端的 ECS 实例中,避免单个实例负载过高。
16.2. Web Service Layer(Web服务层)
ECS Instance(Elastic Compute Service 实例):用于提供 Web 服务的计算实例。SLB 会将用户请求分配到这些 ECS 实例上,处理用户的 Web 服务请求。
Decision Analysis(决策分析)*和*Query Service(查询服务):提供数据查询和决策支持的服务,通过与应用层和数据层交互,帮助用户获得所需的结果。
16.3. Application Service Layer(应用服务层)
ECS Instance Application System(应用系统):主要用于托管核心应用和系统,如业务系统、API 网关等。
ECS Instance Query App(查询应用):用于处理用户的查询请求,可能与后端的数据层进行交互。
ECS Instance BI App(商业智能应用):主要用于商业智能相关的分析任务,通过访问 OLAP 数据仓库来生成分析报告。
16.4. Data Layer(数据层)
OLTP(Online Transaction Processing,联机事务处理):
RDS/DRDS(关系数据库服务/分布式关系数据库服务):用于联机事务处理的数据库系统,存储和管理结构化数据,支持日常业务事务的处理。提供数据库备份和数据刷新功能。
DataBase Backup(数据库备份):用于备份 RDS/DRDS 中的数据。
Interactive Query(交互式查询):
Memcache(缓存服务):通过缓存来提高查询速度,减少对数据库的直接访问。
OSS(Object Storage Service,对象存储服务):用于存储文件、日志和快照等大规模非结构化数据。
TableStore(数据查询服务):为分布式大数据查询提供支持。
OLAP(Online Analytical Processing,联机分析处理):
MaxCompute(大数据计算):用于大规模数据仓库和大数据分析,帮助企业进行复杂的数据分析和挖掘。数据通过 Data Loading(数据加载) 进入 MaxCompute 进行分析处理。
16.5. 数据流向
数据从 OLTP 层(例如 RDS/DRDS 数据库)加载并刷新到缓存(Memcache)和文件存储系统(OSS)中,用于提高查询效率。
在分析场景中,数据通过 数据加载(Data Loading) 流入 MaxCompute,进行大数据分析(OLAP),以支持 BI 应用进行商业分析和决策。
17.Apsara的安全架构
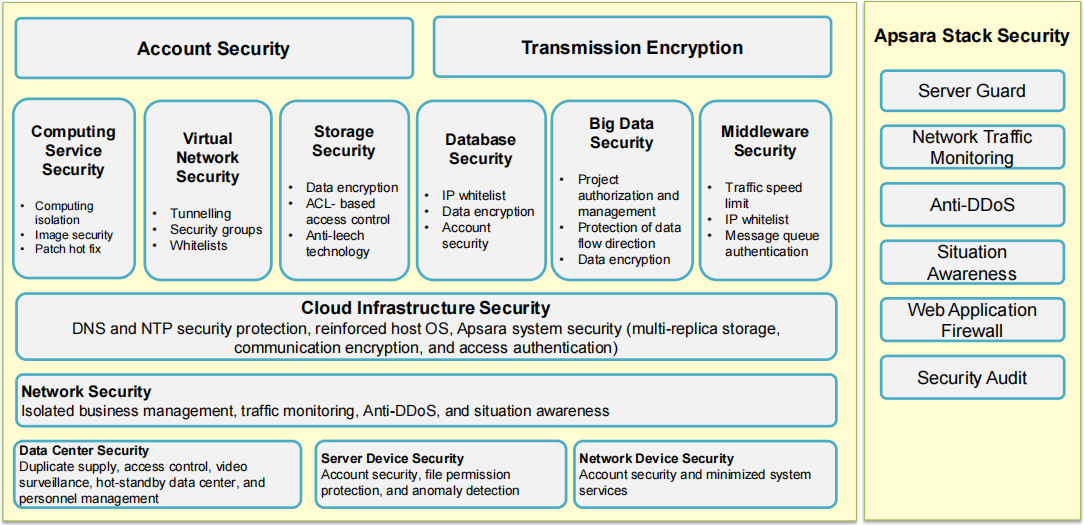
17.1. Account Security(账户安全)
Computing Service Security(计算服务安全):
包含计算隔离、镜像安全和补丁热修复,确保计算资源的独立性和安全性。
Virtual Network Security(虚拟网络安全):
通过隧道、虚拟网络安全组和白名单机制,确保虚拟网络的安全通信和隔离。
Storage Security(存储安全):
包括数据加密、基于 ACL(访问控制列表)的访问控制、防盗链技术等,确保数据存储的安全性。
Database Security(数据库安全):
使用 IP 白名单、数据加密和账户安全等措施来保护数据库。
Big Data Security(大数据安全):
包括项目授权与管理、数据流向保护、数据加密等,保护大数据处理的安全性。
Middleware Security(中间件安全):
包含流量限制、IP 白名单和消息队列认证,确保中间件的安全运行。
17.2. Transmission Encryption(传输加密)
通过加密保护数据在传输中的安全,防止数据在传输过程中被窃取或篡改。
17.3. Cloud Infrastructure Security(云基础设施安全)
提供 DNS 和 NTP 安全保护、强化的主机操作系统、多副本存储、通信加密、访问认证等多种安全机制,确保云基础设施的安全。
17.4. Network Security(网络安全)
通过业务隔离、流量监控、Anti-DDoS(防御分布式拒绝服务攻击)、态势感知等手段保护网络的安全。
17.5. Data Center Security(数据中心安全)
提供冗余电源、访问控制、视频监控、热备数据中心和人员管理,确保物理数据中心的安全性。
17.6. Server Device Security(服务器设备安全)
包含账户安全、文件权限保护和异常检测,保障服务器设备的安全运行。
17.7. Network Device Security(网络设备安全)
保障网络设备的账户安全、最小化系统服务等措施,以确保网络设备的安全。
17.8. Apsara Stack Security(Apsara 云堆栈安全)
提供额外的安全服务,如:
Server Guard(服务器防护)
Network Traffic Monitoring(网络流量监控)
Anti-DDoS(防 DDoS 攻击)
Situation Awareness(态势感知)
Web Application Firewall(Web 应用防火墙)
Security Audit(安全审计)
18.Apsara security 可视化架构
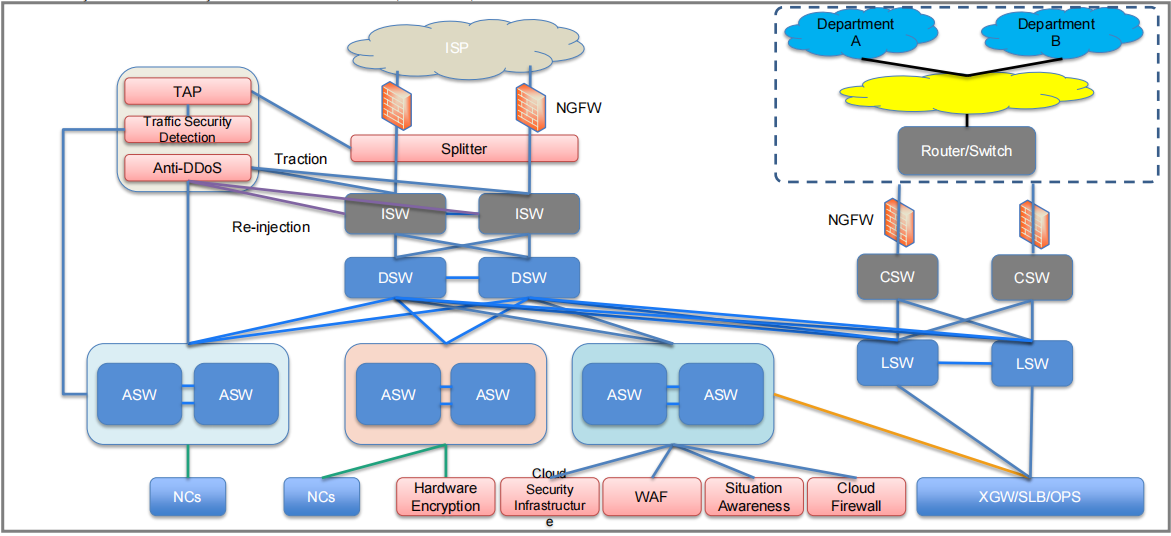
18.1. TAP 和流量管理部分
TAP(流量复制器):用于复制网络流量,用于流量监控或分析,不会对实际网络中的数据流产生影响。
Traffic Security Detection(流量安全检测):用于实时检测网络流量中的安全威胁,监控异常行为或攻击模式。
Anti-DDoS:防御分布式拒绝服务(DDoS)攻击,确保流量正常传输和服务可用性。
18.2. ISP 和 NGFW(Next-Generation Firewall,下一代防火墙)
ISP(Internet Service Provider):连接到互联网服务提供商,用于数据中心或企业网络访问外部网络。
NGFW(下一代防火墙):提供增强的网络安全防护,通常包括深度包检测(DPI)、应用控制、恶意软件防护等功能,以保护企业网络免受攻击。
18.3. Splitter(流量分流器)
Splitter:用于将来自不同网络设备或服务的流量进行分离和重定向,以便更好地管理和监控网络中的流量。
18.4. 网络交换机与层次划分
ISW(Intermediate Switch,中间交换机):用于连接核心交换机和数据中心中的各个模块,通常起到汇聚流量的作用。
DSW(Data Switch,数据交换机):数据交换机,通常连接数据存储或数据库,处理大量的数据流动。
LSW(Local Switch,本地交换机):通常用于接入层,连接部门网络或子网中的设备。
CSW(Core Switch,核心交换机):核心交换机,负责在数据中心或大规模网络中处理主要的流量转发和交换任务。
ASW(Access Switch,接入交换机):用于接入层的交换机,连接最终用户设备或服务器。
18.5. Department A 和 Department B
两个部门的网络通过路由器或交换机连接到主干网络,并通过 NGFW(下一代防火墙)进行安全防护。这些部门可能代表了公司内部不同的业务部门或子网。
18.6. 数据安全与基础设施
NCs(Network Controllers,网络控制器):管理和控制网络中的数据流和策略,确保流量的高效转发与安全性。
Hardware Encryption(硬件加密):用于加密网络通信中的数据,保护敏感信息免受窃听或篡改。
Cloud Security Infrastructure(云安全基础设施):确保企业使用云服务时的安全性,可能包括身份认证、访问控制等。
WAF(Web Application Firewall,Web 应用防火墙):用于保护 Web 应用程序免受攻击,尤其是 SQL 注入、跨站脚本(XSS)等常见攻击。
Situation Awareness(态势感知):实时监控整个网络环境,识别潜在威胁并进行响应。
Cloud Firewall(云防火墙):针对云环境的防火墙服务,提供流量监控、访问控制等功能,确保云中的数据安全。
18.7. XGW/SLB/OPS
XGW(跨网关):跨不同网络或系统的网关设备,用于连接不同网络段或数据中心。
SLB(Server Load Balancer,服务器负载均衡):用于将流量均匀分配到多个服务器,防止某个服务器过载,提升系统的可用性和稳定性。
OPS(Operations,运维管理):用于系统的运维监控和管理,确保整个网络和基础设施的稳定运行。
19.Geo-DR Architecture
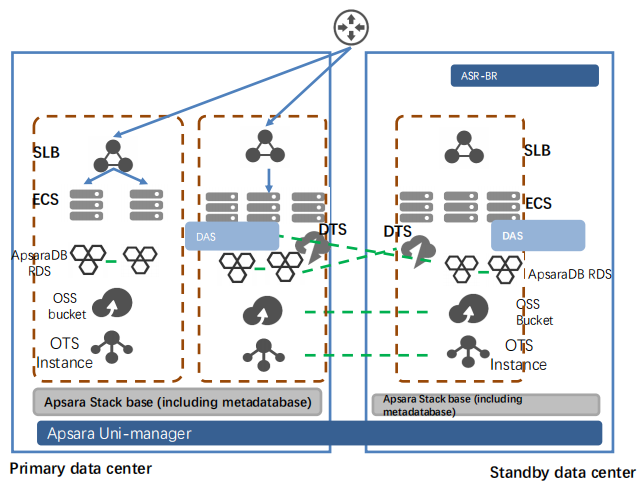
19.1. Primary data center(主数据中心)
SLB(Server Load Balancer):服务器负载均衡器,用于分发流量到不同的 ECS 实例。
ECS(Elastic Compute Service):弹性计算服务,是主数据中心用于运行各种应用和服务的虚拟机实例。
ApsaraDB RDS:云数据库 RDS,用于存储应用程序的结构化数据。
OSS Bucket:对象存储服务(Object Storage Service),用于存储大量的非结构化数据,如文件、图片、视频等。
OTS Instance(Table Store):表格存储服务,提供低延迟的 NoSQL 数据存储解决方案。
DAS(Database Autonomy Service):数据库自治服务,管理数据库运行状态,提供自动优化和运维功能。
DTS(Data Transmission Service):数据传输服务,负责将主数据中心的数据复制或同步到备用数据中心。
Apsara Uni-manager:统一管理平台,负责管理和监控整个基础设施,包含元数据库(metadatabase),确保系统配置和数据的一致性。
19.2. Standby data center(备用数据中心)
ASR-BR(Apsara Stack Region - Backup Recovery):用于灾难恢复的备用数据中心,与主数据中心保持数据同步。
SLB、ECS、ApsaraDB RDS、OSS Bucket、OTS Instance、DAS:备用数据中心与主数据中心类似,部署了相同的组件和服务,用于承载灾难发生时的数据和应用切换。
DTS:负责接收来自主数据中心的实时数据同步,确保备用数据中心的数据与主数据中心一致。
19.3. 数据同步与灾难恢复机制
数据复制(Data Transmission):通过 DTS(Data Transmission Service),主数据中心的数据被实时或定期同步到备用数据中心,确保两者数据一致。
再注入机制(Re-injection):当数据从主数据中心同步到备用数据中心后,数据会被重新注入到备用系统中,以便在灾难发生时可以直接使用。
故障切换:如果主数据中心出现灾难,备用数据中心将承担运行任务,实现业务的无缝切换。
- 0
- 0
-
分享